LLM bots + Next.js image optimization = recipe for bankruptcy (post-mortem)
A misconfiguration that might have cost us $7,000
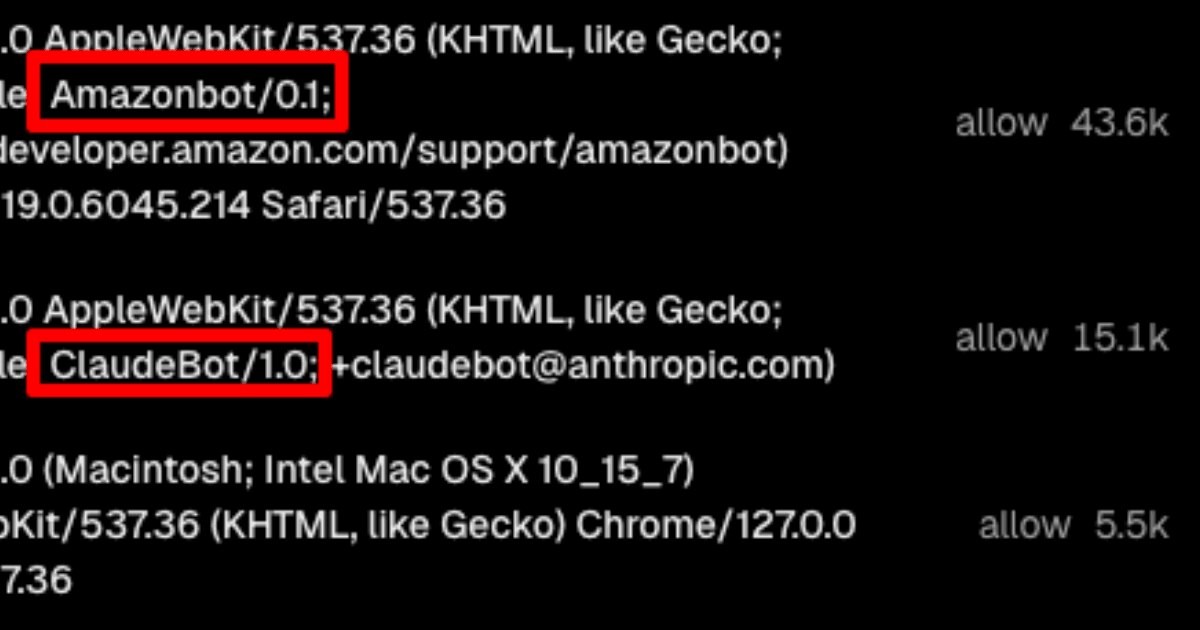

Table of Contents
TL;DR
On Friday, Feb 7, 2025 we had an incident with our Next.js web app hosted on Vercel that could've cost us $7,000 if we didn't notice it in time.
We had a spike in LLM bot traffic coming from Amazonbot, Claudebot, Meta and an unknown bot. Together they sent 66.5k requests to our site within a single day. Bots scraped thousands of images that used Vercel's Image Optimization API, which cost us $5 per 1k images.
The misconfiguration on our side combined with the aggressive bot traffic created an economically risky situation for our tiny bootstrapped startup.
Context
Metacast is a podcast tech startup. Our main product is a podcast app for iOS and Android.
For every podcast episode on the platform, our web app has a web page. Our platform has ~1.4M episodes, which means we have 1.4M web pages that are discoverable by crawlers. These pages are generated server-side at request time, then cached.
How we discovered the problem
Step 1: A cost spike
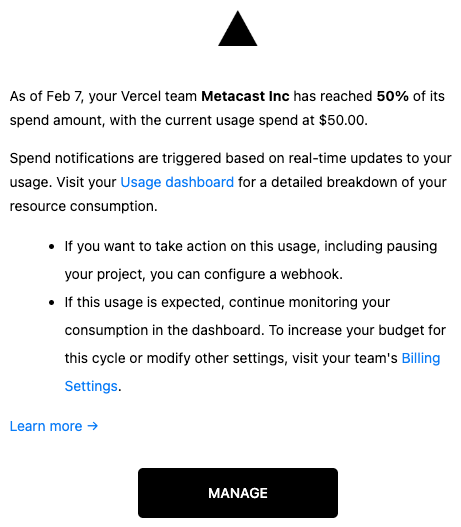
First, we received a cost alert from Vercel saying that we've hit 50% of the budget for resources metered by usage.
Step 2: Image Optimization API usage spike
We looked into it and saw that it's driven by the Image Optimization API, which peaked on Feb 7.
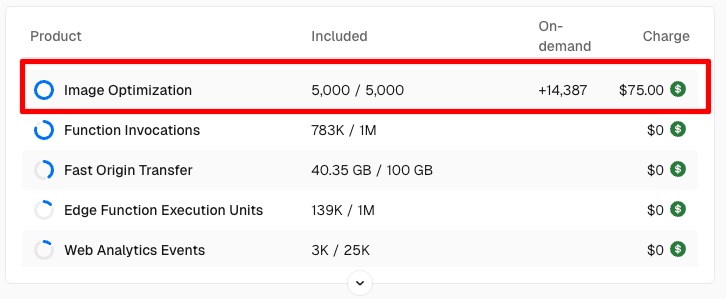

Every page in the podcast directory has an image of a podcast cover (source image dimensions are 3000x3000px). With Image Optimization, podcast covers were reduced to 1/10th of the size, then cached. Image Optimization made the web app really snappy. It worked like a charm, except it turned out to be very expensive.
Vercel charges $5 for every 1,000 images optimized. With thousands of requests coming our way, we were accumulating cost at the rate of $5 per each 1k image requests. In the worst case scenario, if all 1.4M images were crawled we'd hypothetically be looking at a $7k bill from Vercel.
Step 3: Tens of thousands of requests from LLM bots
We looked at the user agents of requests in the Firewall in Vercel and saw Amazonbot, ClaudeBot, meta_externalagent and an unknown bot disguising itself as a browser.
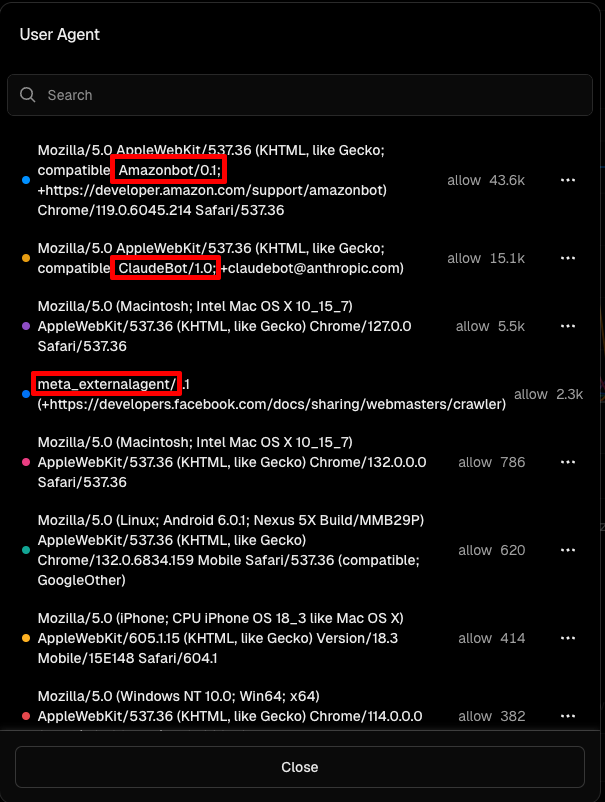
We can't say definitively which bots were downloading images, because we are on the Pro plan on Vercel and no longer have access to logs from Friday. We only know that it was bot traffic.
Mitigation
Step 1: Stop the bleeding
Both of us used to work at AWS where we internalized the golden rule of incident recovery - stop the bleeding first, do a long-term fix later.
We configured firewall rules in Vercel to block bots from Amazon, Anthropic, OpenAI and Meta. To be fair, OpenAI didn't crawl our site, but we blocked it as a preventative measure.
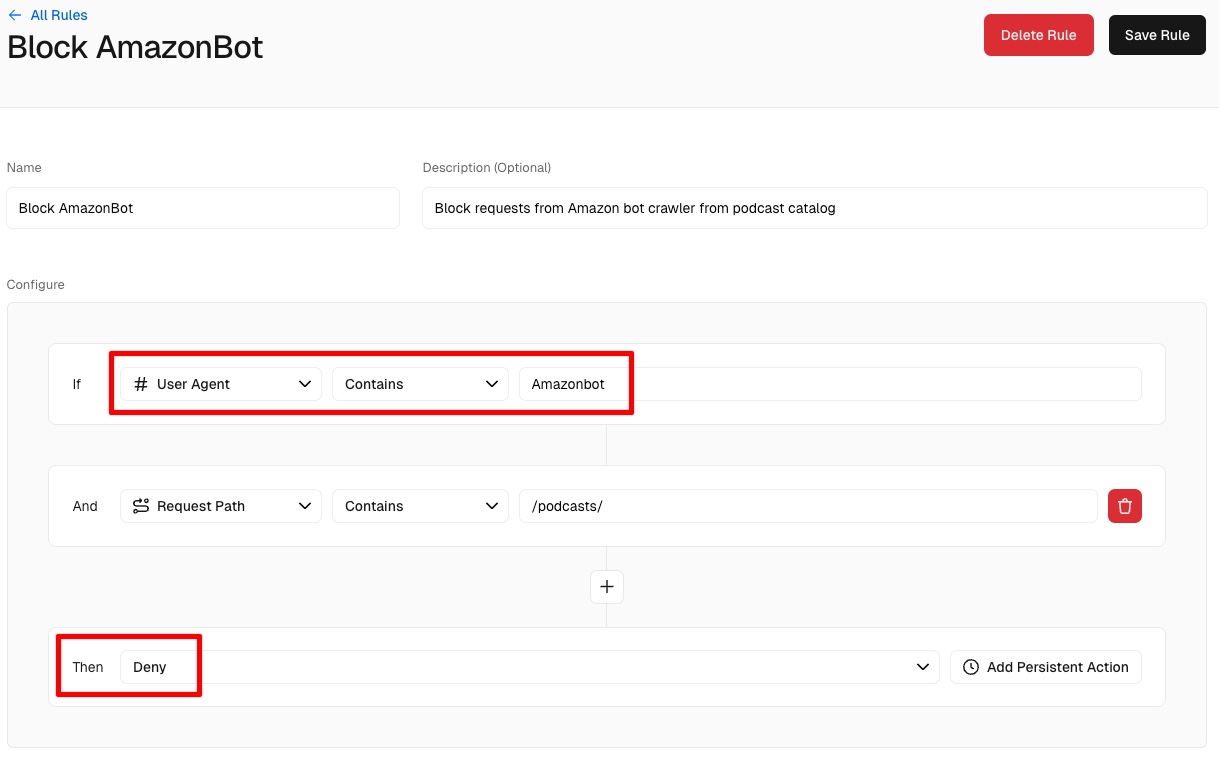
Step 2: Disable Image Optimization
First, we disabled image optimization by adding an unoptimized property to podcast images in Next.js. Our reasoning was that users accessing the pages will get the latest version of the page with unoptimized images.
We didn't consider that:
- Bots had already crawled thousands of pages and would crawl the optimized images using the URLs they extracted from the "old" HTML.
- Our site enabled image optimization for all external hosts.
The latter is the most embarrassing part of the story. We missed an obvious exploit in the web app.
const nextConfig = {
images: {
remotePatterns: [
{
protocol: 'https',
hostname: '**',
},
{
protocol: 'http',
hostname: '**',
},
],
},
...To explain why we did this in the first place, we need to add some important context about podcasting.
We do not own the podcast content displayed on our site. Similar to other podcast apps like Apple and Spotify, we ingest podcast information from RSS feeds and display it in our directory. The cover images are hosted on specialized podcast hosting platforms like Transistor, Buzzsprout, and others. But podcasts could be hosted anywhere from a WordPress website to an S3 bucket. It is impractical to allowlist all possible hosts.
Optimizing an image meant that Next.js downloaded the image from one of those hosts to Vercel first, optimized it, then served to the users. If we wanted to make our site snappy, we had to either build and maintain an image optimization pipeline ourselves or use the built-in capability. As a scrappy startup for whom a web app was at best secondary, we chose the faster route without thinking much about it.
In retrospect, we should've researched how it works. We're lucky no one started using our site as an image optimization API.
To mitigate the problem entirely, we disabled image optimization for any external URLs. Now, image optimization is only enabled for images hosted on our own domain. Podcast covers load noticeably slower. We'll need to do something about it eventually.
But this is not all.
Step 3: robots.txt
Of course, we knew about robots.txt, a file that tells crawlers whether they're allowed to crawl the site or not.
Since both of us were new to managing a large-scale content site (our background is in backends, APIs, and web apps behind auth), we didn't even think about LLM bots. It's just not something that was on our radar. So, our robots.txt was a simple allow-all except for a few paths that we disallowed.
Our first reaction was to disable all bot traffic except Google. But when we understood that the root cause of the problem lied in the misconfigured image optimization, we decided to keep our site open to all LLM and search engine bots. Serving the text content doesn't cost us much, but we may benefit from being shown as a source of data in LLMs, which would be similar to being shown on a search engine results page (SERP).
We generate robots.txt programmatically using robots.ts in Next.js. We researched the bots and added their user agents to our code. If we ever need to disable any of the bots, we can do so very quickly now. While we were at it, we disabled some paths for SEO bots like Semrush and MJ12Bot.
Note that robots.txt only works if bots respect it. It's honor-based system and there are still bad bots out there that ignore it and/or attempt to disguise themselves as users.
User agents of LLM bots
| User Agent | Link |
|---|---|
Amazonbot |
Amazon |
CCBot |
Common Crawl |
ClaudeBot |
Anthropic |
GPTBot |
OpenAI |
Meta-ExternalAgent |
Meta |
PerplexityBot |
Perplexity |
User agents of search engine crawlers
| User Agent | Link |
|---|---|
Applebot |
Apple |
Baiduspider |
Baidu |
Bingbot |
Bing |
ChatGPT-User & OAI-SearchBot |
OpenAI |
DuckDuckBot |
DuckDuckGo |
Googlebot |
|
ImageSift |
ImageSift by Hive |
Perplexity‑User |
Perplexity |
YandexBot |
Yandex |
User agents of SEO bots
| User Agent | Link |
|---|---|
AhrefsBot |
Ahrefs |
DataForSeoBot |
DataForSeoBot |
DotBot |
DotBot |
MJ12bot |
MS12Bot |
SemrushBot |
Semrush |
How do we prevent this in the future?
We will start with the one thing we've done well.
Continue with a sensitive spend limit
We had a very sensitive spend limit alert. We knew we should not be spending much on Vercel, so we set it very low. When it triggered, we knew something was off.
This may be the most important lesson to all startups and big enterprises alike - always set spend limits for your infrastructure, or the bill may ruin you. You can probably negotiate with Vercel, AWS, GCP, etc. and they'll reduce or forgive your bill. But it's best to not put yourself in a situation where you have to ask for a favor.
Mindset for scale
We've learned a ton and have (hopefully) attuned ourselves to:
- The scale we're operating at – we're serving millions of pages and need to be prepared for user traffic at that scale. The bots gave us a taste for what it would've been like had our app gone viral.
- The scale of web crawlers, both good and bad – we need to be prepared to be "anthropized", "openAIed", "amazoned", or "semrushed." It's the new slasdot effect but without the benefit of immediate gratification.
Ready for defense
We've now better understood the options we have for firewalling ourselves from bots if we have to do so in the future. We can use Vercel firewall as the first line of defense or add a more advanced WAF from Cloudflare if things get dire.
See this post from Cloudflare: Declare your AIndependence: block AI bots, scrapers and crawlers with a single click
Social media response
When we discovered the rate at which bots were crawling our site, we posted about it on LinkedIn. We were just sharing what's going on in real time, but boy did it hit the nerve. Almost 400k impressions, 2.4k likes, 270+ comments, 120+ reposts.
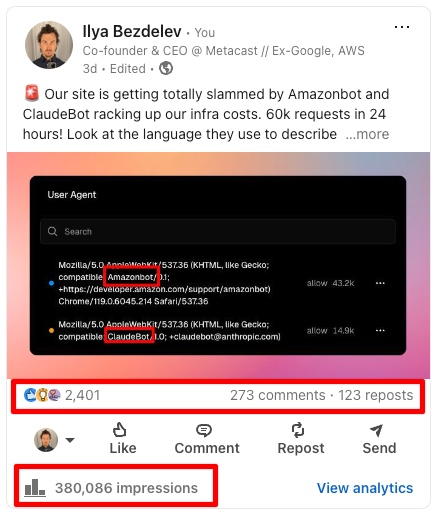
We've gone through all comments on the post and responded to most of them.
Lots of folks offered solutions like CloudFlare, using middleware, rate limiting, etc. Some offered to feed junk back to LLM bots.
We learned about tarpit tools like iocaine and Nepenthes.
You could lure them into a honeypot?
Like nepenthes or locaine.
If you feel like poisoning the ai well
People rightfully pointed out that you can get ruined by infinite scalability of cloud resources.
that's my biggest concern about cloud providers. You make a small mistake (everyone does) and the costs can skyrocket overnight.
We learned that some people aren't aware of the LLM bot crawling activity or the scale of it. They thanked us for raising awareness.
WOW - thanks for alerting us.
Some people had been surprised by bots just like we were.
Same here. At first I was super excited to get so many new subscriptions. We did reCaptcha and Cloudflare. Things have quieted down. Thanks for posting. I thought we were the only ones
Some aren't surprised at all and see it as a problem.
Very recognizable (unfortunately). These (predominantly AI) bots started noticeably hitting our platform back in May/June 2024. Lots of time & efforts wasted to keep our bills in check. We also found out that not all of them respect Robots.txt, so indeed a WAF is needed as well. I can(not) imagine how painful this must/will be for smaller businesses...
Some people blamed us for not being prepared and called us out on calling out AI companies. Others defended us. Virality is a double-edged sword.
A large portion of the comments were claiming that data scraping is unethical, illegal, etc. People were outraged. It wasn't our intention, but our post brought the issue to the zeitgeist of that day.
Parting thoughts
There's a part of me that is glad that this happened.
We got a taste of operating a web app at scale before reaching scale. It was easy to block bots, but had it been caused by user traffic, we'd have to swallow the cost or downgrade the experience. Bots were the canaries in a coalmine.
Any technology has negative externalities.
Some are obvious, some aren't. Of all the things that were happening, I was worried that we'd get penalized by podcast hosters whose endpoints we were hitting at the same rate as bots requested images from our site.
Operating at scale on the internet is a game of defense
We can rant about bots as much as we want, but that is the reality we operate in. So we better acknowledge it and deal with it.
P.S. We'll be discussing this topic on the next episode of the Metacast: Behind the scenes podcast. Follow us wherever you listen to podcasts to hear the story with more nuance.
UPD: Vercel changed their image optimization pricing
On Feb 18, 2025, just a few days after we published this blog post, Vercel changed their image optimization pricing. With the new pricing we'd not have faced a huge bill.
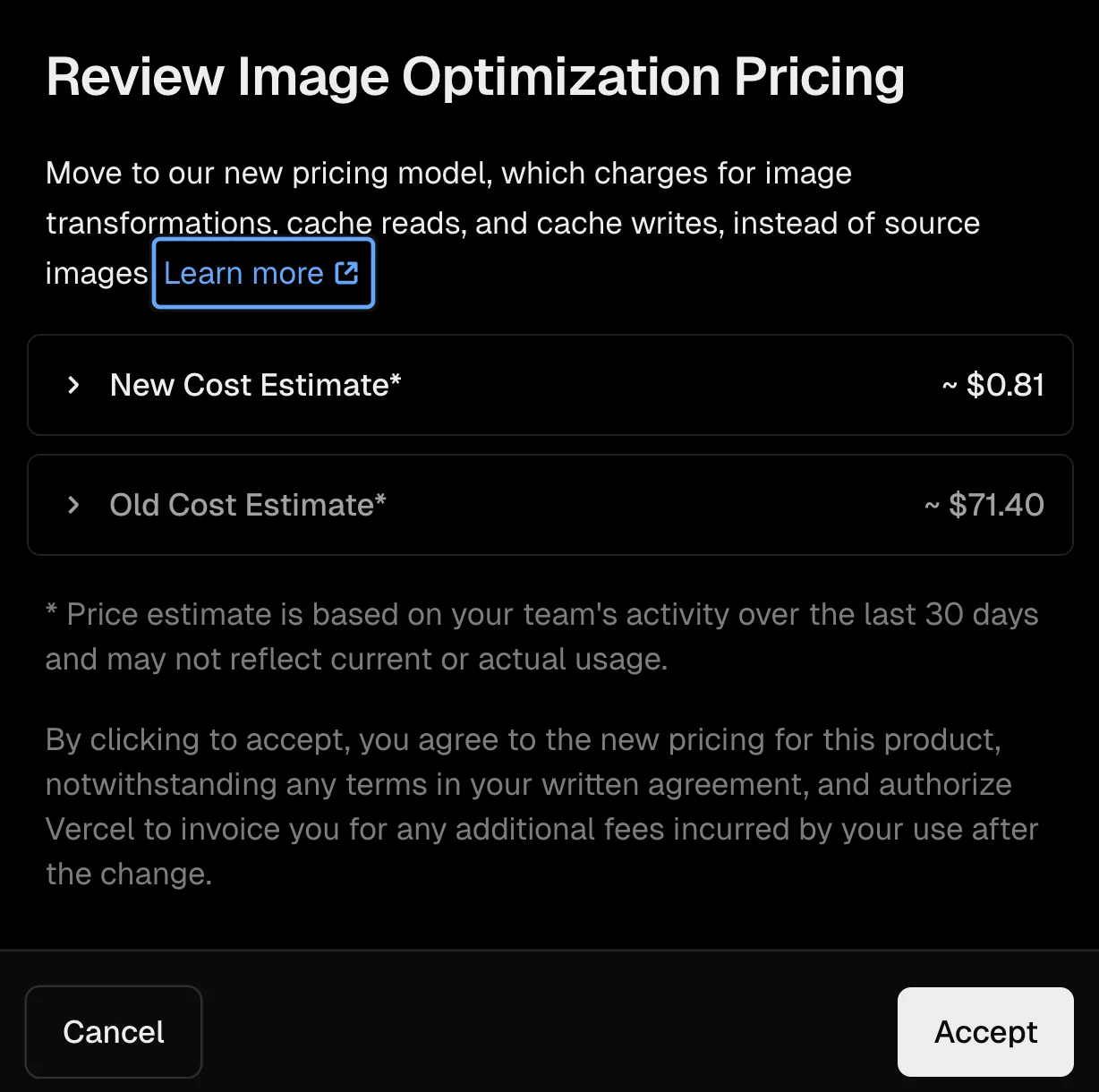
However, this wouldn't address the problem that we need to optimize images hosted outside of our domain. We ended up implementing our own image optimization.
